
Este documento describe paso a paso el análisis y desarrollo de una aplicación J2ee. Se asume que el lector posee los conocimientos previos requeridos sobre tecnología Java/J2ee: JDBC, Struts, Hibernate, EJB, JNDI, etc.
Nuestra Aplicación
Primer vamos a plantear la aplicación que queremos resolver. Basicamente se trata de una aplicacion para “navegar” entre los empleados de una empresa, los departamentos a los que estos pertenecen y las localidades donde los departamentos están ubicados.
Modelo de Datos
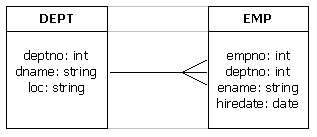
La tabla EMP representa a los empleados de la empresa.
La tabla DEPT representa los departamentos para los cuales trabajan los empleados.
Podemos ver que existe una foreign key (FK) entre las tablas EMP y DEPT. Es decir: un empleado pertenece a un departamento y un departamento tiene varios empleados.
Pantallas de la Aplicación

Esta es la pantalla de ingreso al sistema. El empleado debe identificarse ingresando su número de emplado (empno) y su nombre (ename). Si los datos ingresados son correctos se pasa a la siguiente pantalla.

Una vez que el empleado se identificó correctamente en la pantalla anterior se ingresa a esta pantalla en la que se muestran todos los datos del empleado: número de empleado (empno), nombre (ename), fecha de ingreso (hiredate) y nombre del departamento al que pertenece (DEPT.dname). Si se hace click en el nombre del departamento se pasa a la siguiente pantalla para ver la información del departamento.
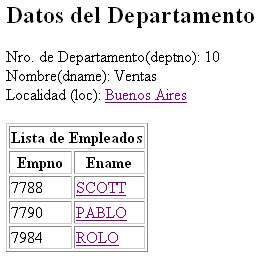
Esta pantalla muestra los datos del departamento. Número de departamento (deptno), nombre (dname) y localidad (loc). También muestra la lista de empleados que pertenecen al departamento indicando por cada uno su número de empleado (empno) y su nombre (ename). Si se hace click en el nombre de alguno de los empleados se regresa a la pantalla anterior y se podrán ver los datos completos del empleado. Si se hace click en el nombre de la localidad se pasa a la siguiente pantalla con la información de la localidad.

Esta pantalla muestra la información de la localidad y la lista de departamentos que allí se ubican. Si se hace click en el nombre de alguno de los departamentos se regresa a la pantalla anterior para visualizar toda la información del departamento seleccionado.
Solución de la Aplicación
Para comenzar plantearemos una solución de n capas. El desarrollo en capas es fundamental para la resolución de aplicaciones grandes. Nos permite asignar responsabilidades a cada capa y de esta manera asumir que cada capa resuelve ciertas cuestiones y abstrae a la capa siguiente de esa problemática.

La capa de Negocios
El gráfico muestra que para resolver la capa de negocios de esta aplicación necesitaremos tres clases: las clases Facade, Dept y Emp.
- clase Facade – Su objetivo es brindar un método por cada caso de uso que deba resolver la aplicación. El facade representa “la aplicación”. Es una “puerta de entrada” a la funcionalidad que provee la aplicación.
- clases Dept, Emp - Podemos ver que tenemos una clase por cada tabla. El objetivo de cada una de estas clases es resolver los accesos (SQL) hacia la tabla que representan. El conjunto de estas clases determina lo que llamaremos “modelo de dominio de la aplicación”.
Objetos DTO (para la transferencia de datos)
Para separar la lógica de acceso a la capa de datos (en nuestro modelo representada por las clases Emp y Dept) de la información contenida en las filas de cada tabla utilizaremos objetos DTO (data transfer object).
Es decir: si la clase Emp tiene un método buscar(), el valor de retorno de este método será una instancia de la clase EmpDTO siendo esta una clase con atributos, setters y getters; o sea: “una estructura” que representa una fila en particular de la tabla Emp.
El siguiente diagrama de secuencia clarifica el uso de los DTO.

La lectura de este diagrama debe realizarse de la siguiente manera:
- El usuario (un programa, un servlet, etc) invoca al método identificarEmpleado() de la clase Facade.
- Este, instancia la clase Emp y le invoca el método buscar().
- La clase Emp realiza el acceso a la base de datos (a través de SQL) y obtiene los datos del empleado.
- Instancia un objeto de tipo EmpDTO y le setea todos los datos que recuperó de la base de datos.
- Retorna al Facade la instancia de EmpDTO cargada con los datos.
- El Facade verifica que el nombre cargado en el dto (dto.getEname()) sea igual al que recibió como parámetro (ename). Si son iguales retorna el dto. Si no retorna null.


Definiendo los Método del Facade
Las pantallas que difinimos para la aplicación nos ayudarán a deducir que métodos debemos resolver en la clase Facade.
Para procesar los datos ingresados en esta pantalla debemos disponer de un método identificarEmpleado() que reciba empno y ename y retorne una instancia de EmpDTO o null si los datos no son correctos.
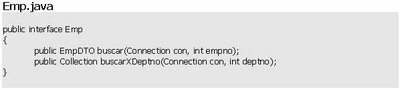
Para mostrar la información de esta pantalla utilizaremos la instancia de EmpDTO que obtuvimos luego de invocar al método identificarEmpleado(). Al hacer click en el nombre del departamento debemos disponer de un método obtenerEmpleados() que reciba deptno y retorne una Collection de EmpDTO. Esta colección la utilizaremos en la próxima pantalla.

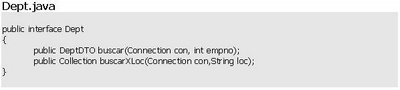
Para poder mostrar los datos del departamento debemos disponer de un método buscarDepartamento() que reciba deptno y retorne una instancia de DeptDTO. Para mostrar la tabla con los empleados del departamento disponemos de la colección que obtuvimos con el método obtenerEmpleados() descripto más arriba. Por último debemos definir de un método obtenerDepartamentos() que reciba loc y retorne una colección de DeptDTO.

La colección de departamentos la obtenemos con el método obtenerDepartamentos() definido más arriba. Es decir: para esta pantalla no necesitamos definir ningún otro método.
Resumiendo, los métodos que debe tener la clase Facade son los siguientes:
Diseño orientado a Contratos
Voy a complicar las cosas un poco más pero prometo, luego de esto, hacer un repaso de todo lo visto hasta aquí.
Cuando tenemos un equipo de desarrollo en el cual cada programador tiene que desarrollar una clase diferente es más que probable que surjan dependencias. Es decir: para que Juan pueda realizar su trabajo necesita disponer de la clase que está programando Raúl, y Raúl necesita la clase que está programando Pedro y así.
Entonces surje la necesidad de poder separar la interface de la implementación de las clases que vayamos a programar.
En nuestra aplicación esto se resuelve definiendo Facade, Emp y Dept no como clases sino como interfaces.

Resumiendo lo que vimos hasta aquí
Dijimos que para resolver la aplicación de los empleados y los departamentos vamos a proponer un desarrollo de n capas. Por ahora solo hemos analizado la capa de negocios.
En la capa de negocios tendremos dos “subcapas”: los objetos de negocio (que representan las tablas del modelo de datos y constituyen lo que se denomina “modelo de dominio de la aplicación”) y el objeto Facade que representa la fachada de la aplicación.
Para mantener una separación entre los datos y los objetos encargados de recuperar esos datos (Dept y Emp) definimos DTOs. (EmpDTO y DeptDTO). Los DTOs son clases que solo tienen atributos, setters y getters. Es decir: son estructuras que representan los registros de las tablas.
Para mantener una separación entre los “servicios” que brindan las clases y la implementación de dichos “servicios” definimos las interfaces por separado. Así tenemos que en realidad Facade, Emp y Dept son interfaces (no clases) y luego tendremos que programar una implementación para cada una de estas interfaces (por ejemplo FacadeImple, EmpImple y DeptImple).
La implementación de Dept y Emp
Analizaremos las clases DeptImple y EmpImple que serán implementaciones de las interfaces Dept y Emp respectivamente.


Ahora vamos a probar el funcionamiento de estas clases con una función main.

Como vemos, la línea Emp e = new EmpImple() no es lo mejor que podríamos esperar... Estamos atando nuestro código (en este caso la función main) a una implementación particular de Emp (EmpImple). Nuestro código debe abstraerse de la implementación por lo tanto debemos encontrar la forma de eliminar las líneas que hacen referencia directa a dicha implementación.
Patrón de Diseño Factory Method
Para resolver el problema anterior y poder desacoplar nuestro código de la implementación crearemos una clase cuyo objetivo será crear los objetos de negocios. Esta clase será una “fábrica de objetos de negocio”.

Ya tenemos nuestra “fábrica de objetos de negocio” que (además) implementa el patrón de diseño Singleton Pattern dado que (como estamos planteando las cosas) a lo largo de toda la aplicación solo necesitaremos una única instancia de Dept y Emp.
Entonces ahora nuestra función main queda así:

Esto resuelve el problema de “harcodear” en nuestro código la implementación particular de una interface.
Implementación de la clase Facade
Siguiendo el mismo razonamiento vamos a programar una implementación y una fábrica para la interface Facade.

Ya estamos disfrutando de los beneficios de haber delegado responsabilidades en las diferentes capas.
Podemos ver lo simple que resulta programar la implementación de Facade gracias a que tenemos resuelto todo el acceso a la base de datos en la capa de objetos de negocio y por lo tanto en esta clase solo programamos a nivel lógico.
El método identificarEmpleado() simplemente verifica que exista el empleado identificado por empno y luego, si existe, controla que coincida su nombre (ename).
En el método buscarDepartamento() solo necesitamos delegar en el método buscar de Dept.
Ahora desarrollaremos una fábrica para obtener una instancia de Facade.

Creación de un cliente de prueba
Con esto tenemos material suficiente como para programar una clase que (provisoriamente) juegue el papel de cliente de la aplicación. Utilizaremos esta clase para probar todos los métodos del facade.

Es un buen momento para un nuevo resumen.
Resumen de lo visto hasta aquí
Diseñamos clases que resuelven el acceso a las tablas del modelo de datos y diseñamos una clase que resuelve la lógica de la aplicación.
Para desacoplar y separar los servicios que provee cada una de estas clases de sus respectivas implementaciones las definimos como interfaces y programamos una implementación concreta para cada una de ellas. Así tenemos las interface: Facade, Dept y Emp y sus correspondientes implementaciones: FacadeImple, DeptImple y EmpImple.
Luego nos encontramos con la necesidad de obtener instancias concretas de Facade, Dept y Emp pero para esto teníamos que “harcodear” los “new FacadeImple(), new EmpImple() y new DeptImple()” lo cual quedaba muy feo dado que ataba nuestro código a esa implementación particular. Esto lo resolvimos creando “fábricas” de instancias implementando así el patrón de diseño Factory Method.
Creamos la clase DomainFactory y FacadeFactory e instanciamos a través de ellas los objetos que necesitamos utilizar.
Para terminar de aclarar las cosas analizaremos el siguiente diagrama de secuencia:

Cambiando las Implementaciones
El hecho utilizar insterfaces y fábricas de instancias que nos permitan abstraer de las implementaciones concretas nos proporciona innumerables beneficios justamente a la hora de cambiar (por cualquier motivo) la implementación.
Ahora.... Que causas pueden motivar un cambio de implementación?
Una implementa temporal
Supongamos que nuestra tarea es programar la implementación de Facade. Por todo lo estudiado hasta aquí es evidente que nuestro trabajo depende de Emp y entonces necesitamos disponer de una implementación concreta de esta clase.
Supongamos ahora que otra persona es la responsable de programar la implementación concreta de Emp y (lamentablemente) aún no esta terminada.
Que hacemos? Detenemos nuestro trabajo hasta que nos faciliten la implementacion de Emp terminada? No me parece lo mejor....
Podemos programar una implementacion temporal de Emp. Algo muy simple pero que nos permita seguir adelante con nuestro código y que luego (cuando la verdadera implementación esté terminada) la reemplazaremos por la implementación real.

Luego, en DomainFactory (nuestra fábrica de objetos de negocio) cambiamos la clase de implementación así:

Ahora podemos revisar la clase FacadeImple.java (que es la clase que nos encargaron desarrollar) y veremos que no se ve afectada en lo más mínimo. Nuestra clase FacadeImple no se entera (y tampoco le interesa enterarse) si DomainFactory le retorna una implementación final o una implementación temporal. Lo único que le interesa es que el factory le entrega una implementación concreta con la que pueda trabajar.
El mismo análisis corresponde si nuestra tarea es programar el cliente y aún no disponemos de la implementación de Facade.
Cambiar la implementación para utilizar otra tecnología
Las implementaciones EmpImple y DeptImple expuestas hasta el momento están resueltas con JDBC plano. Es probable que nos interese resolver el acceso a la base de datos utilizando algún framework de persistencia. Por ejemplo: Hibernate.

Podemos ver que ahora, cambiando convenientemente en DomainFactory, todo nuestro sistema pasa a trabajar con Hibernate sin que esto tenga el más mínimo impacto.

Una aplicación distribuída
Hemos definido la clase Facade como “la puerta de entrada” a la aplicación. Pero la realidad es que hasta ahora Facade solo fue implementada como una clase Java común. Despectivamente podríamos decir que nuestro facade es un POJO.
El hecho de que Facade sea una clase común (o un POJO) nos limita a que solo podremos instanciarlo en la misma máquina virtual.
Miremos nuevamente el gráfico de las n capas para observar otros puntos:

Ahora, en la capa cliente tenemos dos tipos diferentes de cliente.
El Patrón de Diseño Facade
Hasta aquí hemos utilizado la clase Facade para centralizar la lógica de la aplicación en una única clase. Sin saberlo aplicamos el patrón de diseño del Facade que ahora, considerando la posibilidad de tener diferentes tipos de cliente, cobra aún más importancia.
Podemos ver que dos clientes que corren en diferentes host se comunican con el mismo Facade para invocar sus métodos y así poder interactuar con la aplicación.
Esto implica (tasitamente) que debemos implementar alguna solución de objetos distribuídos. Implementaremos el facade como un Session EJB.
Cualquier cambio en la lógica de algún caso de uso implica una modificación en algún método del facade y dado que todos los clientes utilizan el mismo facade el impacto será simultaneo para todos. El uso del facade incrementa la mantenibilidad de nuestro sistema.
Implementando el Facade como un Session Stateless EJB
Tenemos la excusa perfecta para cambiar la implementación del facade. Nuestro análisis debe focalizarse en como (luego de programar el Facade como EJB) minimizar el impácto que pueda generar en los clisentes el uso de esta nueva implementación.


Antes de incorporar esta implementación a nuestra aplicación analicemos un main que haga el lookup (instancie) del EjbFacade y le invoque el método identificarEmpleado.

Como podemos ver, en un main no resulta tan simple abstraerse de que (en este caso) la implementación del facade es un EJB. Tener que inicializar el contexto JNDI, hacer el lookup, obtener la interface home y por último obtener la interface remota es suficientemente engorroso como para distraernos de nuestro objetivo (en este caso programar la función main).
Ahora nos concentraremos en ocultar toda esta complejidad de forma tal que resulte totalmente transparente para el cliente.
El patrón de diseño ServiceLocator
Utilizaremos este patrón de diseño para encapsular la instanciación (o mejor dicho el “lookup”) de un EJB.
La idea es simple: una clase (es este caso la llamaremos ServiceLocator) con un método estático getService() que reciba el nombre JNDI del EJB y la clases (class) de su interface home.
Pero aprovechando que siempre utilizaremos esta clase para hacer el lookup de nuestros EJB podemos sumarle una funcionalidad extra: caché de interfaces home.
Podemos ver que la interface home funciona como una fábrica de instancias remotas, de forma tal que con una única instancia de home podemos crear múltiples instancias remotas. Si consideramos que hacer un lookup implica un overhead importante podríamos minimizar este costo haciendo el lookup una sola vez por EJB.
La clase ServiceLocator que se describe a continuación tiene una tabla de hash en cual va a guardar punteros a las interfaces home de los EJBs a medida que se vayan pidiendo.
Por cada EJB que se pide (a través del método getService) primero se fija si existe una entrada en la tabla de hash con key igual al nombre JNDI del EJB.
Si no existe significa que es la primera vez que se está pidiendo el EJB entonces se hace el lookup y antes de retornar la interface home se la guarda en la tabla de hash asociada en su nombre de JNDI como key.
Si existe significa que este EJB ya se habia pedido antes y tenemos guardado un pontero a su interface home, por lo tanto no será necesario volver a hacer el lookup para obtener una instancia remota..

Volvamos a nuestra clase SimpleMain para ver como utilizamos el ServiceLocator para obtener una instancia del EjbFacade.

Patrón de diseño Business Delegate
Utilizaremos este patrón de diseño para lograr abstraernos por completo de la implementación.
El patrón de diseño propone escribir una clase Java común (un POJO) que “wrappee” los métodos de la interface remota del EJB (los “business methods”) y los resuelva delegando en los métodos reales del EJB. Vendría bien un diagrama de secuencias.....

Notemos una cosa más: Además de wrappear todos los métodos de negocio del EjbFacade hicimos que FacadeDelegator implemente la interface Facade. Por lo tanto podemos decir que “una instancia de FacadeDelegator es una instancia válida de Facade”. Entonces podemos volver a nuestra fábrica de facados FacadeFactory y cambiar la creación del objeto que implementa el facade por una instancia de FacadeDelegator.

Y ahora podemos volver a nuestro cliente original (ClienteTemp) y verificar que todo esto le resulta totalmente transparente.

Como vemos, el cliente es exactamente el mismo que antes y no tiene por que enterarse del hecho de que (ahora) el método identificarEmpleado está ejecutandose en forma remota, en otro host y detrás de un EJB.
La única diferencia es la siguiente: la conexión a la base de datos.
Todos los métodos que definimos en el facade reciben una conexión jdbc. Cuando facade se ejecuta localmente (como un POJO) la conexión debe ser local pero ahora que el facade es un EJB la conexión se resuelve en el container.
- public EmpDTO identificarEmpleado(Connection con, int empno, String ename);
- public Collection obtenerEmpleados(Connection con, int deptno);
- public DeptDTO buscarDepartamento(Connection con, int deptno);
- public Collection obtenerDepartamentos(Connection con, String loc);
Diseño orientado a Contratos
Voy a complicar las cosas un poco más pero prometo, luego de esto, hacer un repaso de todo lo visto hasta aquí.
Cuando tenemos un equipo de desarrollo en el cual cada programador tiene que desarrollar una clase diferente es más que probable que surjan dependencias. Es decir: para que Juan pueda realizar su trabajo necesita disponer de la clase que está programando Raúl, y Raúl necesita la clase que está programando Pedro y así.
Entonces surje la necesidad de poder separar la interface de la implementación de las clases que vayamos a programar.
En nuestra aplicación esto se resuelve definiendo Facade, Emp y Dept no como clases sino como interfaces.


Resumiendo lo que vimos hasta aquí
Dijimos que para resolver la aplicación de los empleados y los departamentos vamos a proponer un desarrollo de n capas. Por ahora solo hemos analizado la capa de negocios.
En la capa de negocios tendremos dos “subcapas”: los objetos de negocio (que representan las tablas del modelo de datos y constituyen lo que se denomina “modelo de dominio de la aplicación”) y el objeto Facade que representa la fachada de la aplicación.
Para mantener una separación entre los datos y los objetos encargados de recuperar esos datos (Dept y Emp) definimos DTOs. (EmpDTO y DeptDTO). Los DTOs son clases que solo tienen atributos, setters y getters. Es decir: son estructuras que representan los registros de las tablas.
Para mantener una separación entre los “servicios” que brindan las clases y la implementación de dichos “servicios” definimos las interfaces por separado. Así tenemos que en realidad Facade, Emp y Dept son interfaces (no clases) y luego tendremos que programar una implementación para cada una de estas interfaces (por ejemplo FacadeImple, EmpImple y DeptImple).
La implementación de Dept y Emp
Analizaremos las clases DeptImple y EmpImple que serán implementaciones de las interfaces Dept y Emp respectivamente.


Ahora vamos a probar el funcionamiento de estas clases con una función main.

Como vemos, la línea Emp e = new EmpImple() no es lo mejor que podríamos esperar... Estamos atando nuestro código (en este caso la función main) a una implementación particular de Emp (EmpImple). Nuestro código debe abstraerse de la implementación por lo tanto debemos encontrar la forma de eliminar las líneas que hacen referencia directa a dicha implementación.
Patrón de Diseño Factory Method
Para resolver el problema anterior y poder desacoplar nuestro código de la implementación crearemos una clase cuyo objetivo será crear los objetos de negocios. Esta clase será una “fábrica de objetos de negocio”.

Ya tenemos nuestra “fábrica de objetos de negocio” que (además) implementa el patrón de diseño Singleton Pattern dado que (como estamos planteando las cosas) a lo largo de toda la aplicación solo necesitaremos una única instancia de Dept y Emp.
Entonces ahora nuestra función main queda así:

Esto resuelve el problema de “harcodear” en nuestro código la implementación particular de una interface.
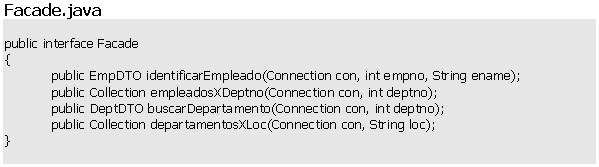
Implementación de la clase Facade
Siguiendo el mismo razonamiento vamos a programar una implementación y una fábrica para la interface Facade.

Ya estamos disfrutando de los beneficios de haber delegado responsabilidades en las diferentes capas.
Podemos ver lo simple que resulta programar la implementación de Facade gracias a que tenemos resuelto todo el acceso a la base de datos en la capa de objetos de negocio y por lo tanto en esta clase solo programamos a nivel lógico.
El método identificarEmpleado() simplemente verifica que exista el empleado identificado por empno y luego, si existe, controla que coincida su nombre (ename).
En el método buscarDepartamento() solo necesitamos delegar en el método buscar de Dept.
Ahora desarrollaremos una fábrica para obtener una instancia de Facade.

Creación de un cliente de prueba
Con esto tenemos material suficiente como para programar una clase que (provisoriamente) juegue el papel de cliente de la aplicación. Utilizaremos esta clase para probar todos los métodos del facade.

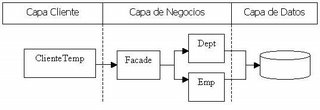
Incorporemos al gráfico de las n capas la capa cliente.
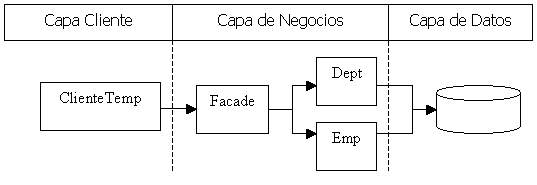
Es un buen momento para un nuevo resumen.
Resumen de lo visto hasta aquí
Diseñamos clases que resuelven el acceso a las tablas del modelo de datos y diseñamos una clase que resuelve la lógica de la aplicación.
Para desacoplar y separar los servicios que provee cada una de estas clases de sus respectivas implementaciones las definimos como interfaces y programamos una implementación concreta para cada una de ellas. Así tenemos las interface: Facade, Dept y Emp y sus correspondientes implementaciones: FacadeImple, DeptImple y EmpImple.
Luego nos encontramos con la necesidad de obtener instancias concretas de Facade, Dept y Emp pero para esto teníamos que “harcodear” los “new FacadeImple(), new EmpImple() y new DeptImple()” lo cual quedaba muy feo dado que ataba nuestro código a esa implementación particular. Esto lo resolvimos creando “fábricas” de instancias implementando así el patrón de diseño Factory Method.
Creamos la clase DomainFactory y FacadeFactory e instanciamos a través de ellas los objetos que necesitamos utilizar.
Para terminar de aclarar las cosas analizaremos el siguiente diagrama de secuencia:

- El cliente pide a FacadeFactory una instancia concreta de Facade. El cliente no sabe cual es la implementación que está recibiendo. Lo único que le interesa es que el objeto que recibe implementa los métodos definidos en la interface Facade y por lo tanto puede ver al objeto como una instanacia válida de Facade.
- Teniendo la instancia de Facade le invoca el método identificarEmpleado().
- La instancia de Facade necesita utilizar el objeto de negocio Emp. Para esto le pide a la fábrica de instancias de dominio (DomainFactory) una instancia concreta que implemente la interface Emp.
- Teniendo la instancia concreta de Emp le invoca el método buscar() para luego obtener el DTO (o null si falló la indetificación).
Cambiando las Implementaciones
El hecho utilizar insterfaces y fábricas de instancias que nos permitan abstraer de las implementaciones concretas nos proporciona innumerables beneficios justamente a la hora de cambiar (por cualquier motivo) la implementación.
Ahora.... Que causas pueden motivar un cambio de implementación?
Una implementa temporal
Supongamos que nuestra tarea es programar la implementación de Facade. Por todo lo estudiado hasta aquí es evidente que nuestro trabajo depende de Emp y entonces necesitamos disponer de una implementación concreta de esta clase.
Supongamos ahora que otra persona es la responsable de programar la implementación concreta de Emp y (lamentablemente) aún no esta terminada.
Que hacemos? Detenemos nuestro trabajo hasta que nos faciliten la implementacion de Emp terminada? No me parece lo mejor....
Podemos programar una implementacion temporal de Emp. Algo muy simple pero que nos permita seguir adelante con nuestro código y que luego (cuando la verdadera implementación esté terminada) la reemplazaremos por la implementación real.
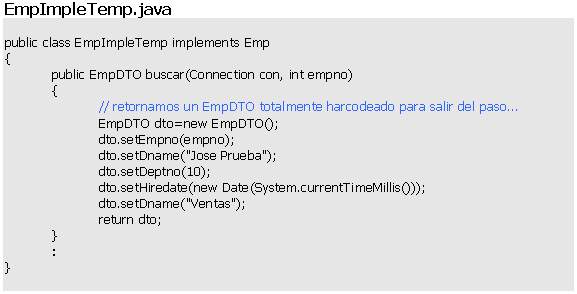
Luego, en DomainFactory (nuestra fábrica de objetos de negocio) cambiamos la clase de implementación así:

Ahora podemos revisar la clase FacadeImple.java (que es la clase que nos encargaron desarrollar) y veremos que no se ve afectada en lo más mínimo. Nuestra clase FacadeImple no se entera (y tampoco le interesa enterarse) si DomainFactory le retorna una implementación final o una implementación temporal. Lo único que le interesa es que el factory le entrega una implementación concreta con la que pueda trabajar.
El mismo análisis corresponde si nuestra tarea es programar el cliente y aún no disponemos de la implementación de Facade.
Cambiar la implementación para utilizar otra tecnología
Las implementaciones EmpImple y DeptImple expuestas hasta el momento están resueltas con JDBC plano. Es probable que nos interese resolver el acceso a la base de datos utilizando algún framework de persistencia. Por ejemplo: Hibernate.

Podemos ver que ahora, cambiando convenientemente en DomainFactory, todo nuestro sistema pasa a trabajar con Hibernate sin que esto tenga el más mínimo impacto.

Una aplicación distribuída
Hemos definido la clase Facade como “la puerta de entrada” a la aplicación. Pero la realidad es que hasta ahora Facade solo fue implementada como una clase Java común. Despectivamente podríamos decir que nuestro facade es un POJO.
El hecho de que Facade sea una clase común (o un POJO) nos limita a que solo podremos instanciarlo en la misma máquina virtual.
Miremos nuevamente el gráfico de las n capas para observar otros puntos:
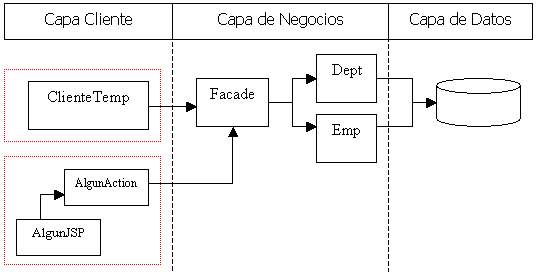
Ahora, en la capa cliente tenemos dos tipos diferentes de cliente.
- ClienteTemp – Es la aplicación standalone que utilizamos hasta ahora.
- AlgunJSP / AlgunAction - Es un cliente web (que en este caso utiliza Struts)
El Patrón de Diseño Facade
Hasta aquí hemos utilizado la clase Facade para centralizar la lógica de la aplicación en una única clase. Sin saberlo aplicamos el patrón de diseño del Facade que ahora, considerando la posibilidad de tener diferentes tipos de cliente, cobra aún más importancia.
Podemos ver que dos clientes que corren en diferentes host se comunican con el mismo Facade para invocar sus métodos y así poder interactuar con la aplicación.
Esto implica (tasitamente) que debemos implementar alguna solución de objetos distribuídos. Implementaremos el facade como un Session EJB.
Cualquier cambio en la lógica de algún caso de uso implica una modificación en algún método del facade y dado que todos los clientes utilizan el mismo facade el impacto será simultaneo para todos. El uso del facade incrementa la mantenibilidad de nuestro sistema.
Implementando el Facade como un Session Stateless EJB
Tenemos la excusa perfecta para cambiar la implementación del facade. Nuestro análisis debe focalizarse en como (luego de programar el Facade como EJB) minimizar el impácto que pueda generar en los clisentes el uso de esta nueva implementación.
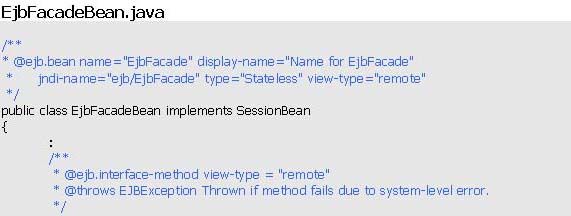


Antes de incorporar esta implementación a nuestra aplicación analicemos un main que haga el lookup (instancie) del EjbFacade y le invoque el método identificarEmpleado.

Como podemos ver, en un main no resulta tan simple abstraerse de que (en este caso) la implementación del facade es un EJB. Tener que inicializar el contexto JNDI, hacer el lookup, obtener la interface home y por último obtener la interface remota es suficientemente engorroso como para distraernos de nuestro objetivo (en este caso programar la función main).
Ahora nos concentraremos en ocultar toda esta complejidad de forma tal que resulte totalmente transparente para el cliente.
El patrón de diseño ServiceLocator
Utilizaremos este patrón de diseño para encapsular la instanciación (o mejor dicho el “lookup”) de un EJB.
La idea es simple: una clase (es este caso la llamaremos ServiceLocator) con un método estático getService() que reciba el nombre JNDI del EJB y la clases (class) de su interface home.
Pero aprovechando que siempre utilizaremos esta clase para hacer el lookup de nuestros EJB podemos sumarle una funcionalidad extra: caché de interfaces home.
Podemos ver que la interface home funciona como una fábrica de instancias remotas, de forma tal que con una única instancia de home podemos crear múltiples instancias remotas. Si consideramos que hacer un lookup implica un overhead importante podríamos minimizar este costo haciendo el lookup una sola vez por EJB.
La clase ServiceLocator que se describe a continuación tiene una tabla de hash en cual va a guardar punteros a las interfaces home de los EJBs a medida que se vayan pidiendo.
Por cada EJB que se pide (a través del método getService) primero se fija si existe una entrada en la tabla de hash con key igual al nombre JNDI del EJB.
Si no existe significa que es la primera vez que se está pidiendo el EJB entonces se hace el lookup y antes de retornar la interface home se la guarda en la tabla de hash asociada en su nombre de JNDI como key.
Si existe significa que este EJB ya se habia pedido antes y tenemos guardado un pontero a su interface home, por lo tanto no será necesario volver a hacer el lookup para obtener una instancia remota..

Volvamos a nuestra clase SimpleMain para ver como utilizamos el ServiceLocator para obtener una instancia del EjbFacade.

Patrón de diseño Business Delegate
Utilizaremos este patrón de diseño para lograr abstraernos por completo de la implementación.
El patrón de diseño propone escribir una clase Java común (un POJO) que “wrappee” los métodos de la interface remota del EJB (los “business methods”) y los resuelva delegando en los métodos reales del EJB. Vendría bien un diagrama de secuencias.....

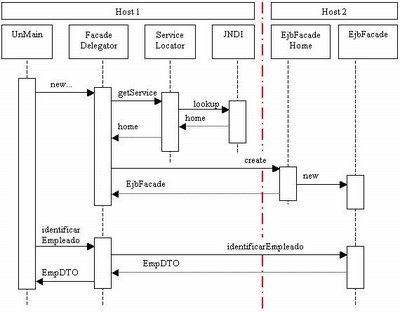
- El main instancia un FacadeDelegator que es una clase Java comun (un POJO).
- En el contructor, el FacadeDelegator utiliza el ServiceLocator para obtener la interface home del EJB que wrappea.
- A través de la interface home obtiene una instancia remota del EJB.
- El cliente invoca el método identificarEmpleado en su instancia de FacadeDelegator.
- FacadeDelegator delega la resolución del método identificarEmpleado invocando al mismo método pero en EjbFacade.

Notemos una cosa más: Además de wrappear todos los métodos de negocio del EjbFacade hicimos que FacadeDelegator implemente la interface Facade. Por lo tanto podemos decir que “una instancia de FacadeDelegator es una instancia válida de Facade”. Entonces podemos volver a nuestra fábrica de facados FacadeFactory y cambiar la creación del objeto que implementa el facade por una instancia de FacadeDelegator.

Y ahora podemos volver a nuestro cliente original (ClienteTemp) y verificar que todo esto le resulta totalmente transparente.

Como vemos, el cliente es exactamente el mismo que antes y no tiene por que enterarse del hecho de que (ahora) el método identificarEmpleado está ejecutandose en forma remota, en otro host y detrás de un EJB.
La única diferencia es la siguiente: la conexión a la base de datos.
Todos los métodos que definimos en el facade reciben una conexión jdbc. Cuando facade se ejecuta localmente (como un POJO) la conexión debe ser local pero ahora que el facade es un EJB la conexión se resuelve en el container.


{kind=link}